
At SS&C Eze, we strive to foster a culture of technical leadership and innovation. We challenge our employees to stretch their imaginations and capabilities in new ways so we can better assist our clients in growing their businesses. Our R&D teams are actively exploring ways to apply artificial intelligence and machine learning both internally in our software development process and externally with new products and features that benefit clients. Our focus has been on developing intelligence systems with practical, easy-to-understand use cases such as identifying best execution broker algos based on order characteristics, load balancing horizontally scalable servers, and finding bugs.
In a previous blog post, Rob Baxter, Director of EMS Engineering, discussed machine learning basics, how supervised and unsupervised learning work, and the factors that have led to rapid adoption of these techniques in recent years. Today, we’ll discuss a recent machine learning project conducted under our “Swing for the Fences” initiative, a unique program where self-organized employee groups pitch ideas for new features or products using cutting-edge technologies and concepts. The goal is to encourage risk-taking and exploration. In the context of Christensen’s Innovator’s Dilemma, the “Swing for the Fences” initiative is one mechanism that enables our R&D organization to create disruptive technologies.

A recent “Swing for the Fences” project continued in this tradition, with the team exploring machine learning models that recommend order routing rules based on a client’s trade history. The idea was inspired by the recently introduced Eze EMS Automated Trading platform, which delivered effective, easy to configure, rules-based order routing designed to augment human behavior, persist operational knowledge, and leave traders with more time to focus on high-value tasks. With the new intuitive interface, traders can easily create and manage rules that automatically route orders to broker destinations.
This marked an exciting evolution of our rules-based order routing capabilities by empowering traders to build their own automated workflows to handle low-touch order flow in highly liquid securities and freeing them up to work more difficult trades manually. But a group of employees wondered if they could take the evolution even further. What unique insights could be gained from analyzing a firm’s trading history and behavior, and how can that knowledge be used to assist them in achieving best execution?
A team of engineers and product managers with experience and knowledge spanning the trading domain as well as mathematics, software, and machine learning, embarked on a journey with modern technology and tools to help clients discover actionable insights about their trading behavior.
Decision Support Systems for Automated Trading
Advances in modern machine learning paradigms have favored approaches where symbiotic relationships are formed between users and intelligent software systems. One area where this has been applied successfully is in Decision Support Systems (DSS), which interact with users to learn and improve automated decision making. A DSS can provide stability and competitive advantage by acting as living repositories for domain knowledge and strategic operation practices as the workforce faces challenges, ages, and turns over. Additionally, a DSS frees up individuals to work on important and challenging tasks.
Eze’s Automated Trading platform is one example of a DSS, which allows users to encode domain knowledge and strategic operational practices into rules that are executed in real time to ensure accurate, predictable, and desired trading behavior. Our team identified the human-readable rules that the platform employs as an opportunity to extend insight and understanding into trading behavior using machine learning. Using this technology, we could discover actionable decision rules from historical trade data, which could then be suggested to users as rules for deployment.
Discovering Routing Rules Using Machine Learning Powered Algorithms
Due to the non-deterministic nature of AI, the need for transparency and interpretability in machine learning systems is paramount, especially in high-risk environments. The level of interpretability in these systems dictates the type of algorithms that can be used to prepare data and engineer new features for the learning process. For data preparation and feature engineering, this means that the results of data transformations and new variables created must be both meaningful and interpretable to some degree. In general, machine learning algorithms exhibit a tradeoff between accuracy and interpretability, meaning a highly accurate algorithm may have low interpretability and vice versa. Tradeoffs and balance must be made between accuracy and interpretability to achieve the desired outcomes and effectiveness of applications.
In practice, established analysis and modeling pipelines vary by organization size and experience. A high-level view of the pipeline used by Eze’s engineers can be seen in the following image.
.jpg?width=788&name=ML%201%20(1).jpg)
Data Ingestion
Although it comes as a surprise to machine learning enthusiasts using prepared data sets provided by their courses and tutorials, in almost all instances, it is necessary to do your own, proprietary data preparation before feeding it to machine learning algorithms. The “80/20” rule generally describes the percentage of time dedicated to data preparation and machine learning modeling respectively. After data is extracted from its source, it is scaled, encoded, and transformed such that it can be used by algorithms.
Analysis
The data is then analyzed using various statistical and machine learning techniques to gain understanding of the relationships between variables. Highly correlated variables are often considered redundant and can be eliminated or compressed using dimensionality reduction techniques such as Principal Component Analysis (PCA) and Projection to Latent Structure (PLS). Reducing dimensions not only lowers data storage costs but also has the additional benefit of decreasing learning processing time. Finally, randomly dividing the data into training and validation sets is crucial for validating that the trained algorithms can generalize to unseen data.
In our project, we employed PLS for data analysis. PLS is similar to the well-known unsupervised PCA technique, but as a supervised algorithm, it fits to both the input and response variables. Although PLS reduces dimensionality, it can be also used for other purposes, such as visualizing data with control charts to glean insights into the statistical populations within the data. Specifically, our team used PLS to identify candidate variables for feature engineering.
Feature Engineering
Once the data is analyzed, new features are engineered based on existing features, creating new data that was not included in the original data set. Once features are engineered and the data is reanalyzed, the variable selection process removes variables that are deemed to be unimportant by use of several machine learning and statistical techniques. Iterative modeling, in which algorithms and workflows are selected and model parameters are optimized, then takes place.
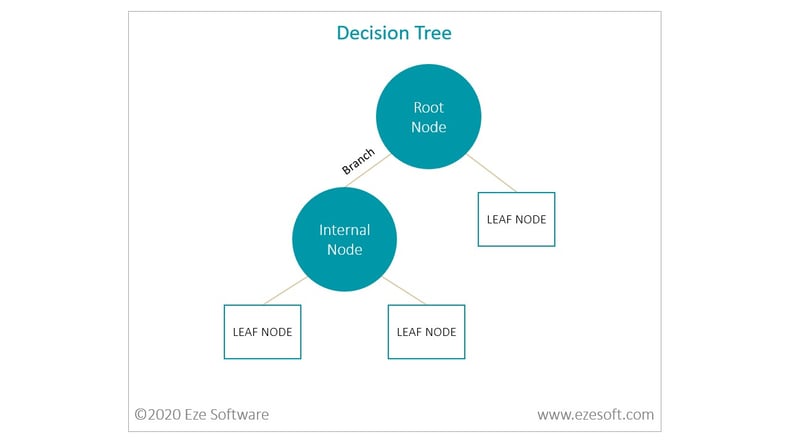
Some of the modeling algorithms used by our team belong to the family of decision trees. Decision Trees are predictive modeling and classification algorithms that learn decision rules by statistically inferring them from data. Their advantages include being easy to visualize, interpret, and explain to non-technical individuals while providing accuracy. In addition, their internal structure can easily be represented as sets of if-then rules, making them an ideal starting point for exploring interpretable machine-generated rules.
Decision trees consist of root nodes, test nodes, branches, and leaf nodes. The top-most node is the root node. Each test, or internal, node stemming off of the root node represents a test of some attribute of the data. Branches that extend from these nodes connect to test nodes and leaf nodes which represent potential outcomes of each test. Each node can then be considered a rule and each path from the root node to a leaf node can be considered a set of rules for classifying an outcome.
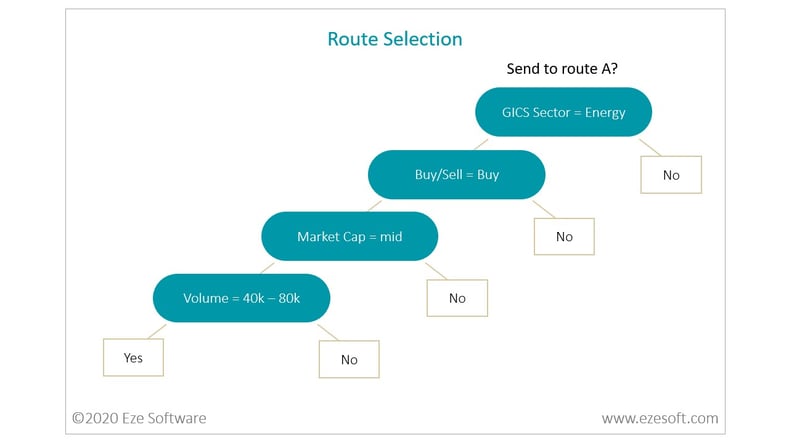
Even after a mature algorithm has been selected, there are still important considerations that must be addressed in order to achieve a high-quality model. Model hyperparameters, parameters that control the learning process, must be tried, tested, and tuned to achieve optimal results. An example of one of several decision tree hyperparameters is the maximum tree depth (number of child nodes along a path from root to leaf). This parameter is important as a shallow tree may not allow the algorithm to capture patterns and interactions within the data, while a tree that is too deep might overfit the training data and not allow it to generalize to data outside of the training set.
Another important hyperparameter concerns the pruning of subtrees within a decision tree that provide low classification power. As the estimated error for a subtree is the sum of misclassification error for all leaf nodes under it, replacement of a subtree with a leaf node, i.e. pruning, can lead to overall improved accuracy and lower classification error when performance over all paths in the tree are considered. A process called cross validation is used to determine the optimal tree depth, the pruning parameter, and other hyperparameters to help ensure the model is robust. Often, a multivariate grid search-based cross validation approach is employed as the several optimal hyperparameter settings are not known ahead-of-time and can only be found with trial and error.
After exploring standard decision trees, our team took the concept further and invented a unique workflow to generate text-based rules from decision tree output. This approach entailed creating a random forest with as many as 300 distinct decision trees. Rulesets for each outcome were scored using various performance metrics from which a single score was then generated. The most performant rulesets for each outcome in all the trees were then filtered by a score threshold, followed by rule deduplication and translation to text. The machine generated rules were then output by the algorithm in a human readable format. For example, the algorithm might output a rule suggestion in the following format: “IF GICS_Sector = Energy AND BuySell = Buy AND Market_Cap = Mid AND Volume_Range = 43000-75000 THEN SEND Route_A”. Upon human inspection of the best text-based decision rules, it was found that some rules were meaningful while others were terse and did not meet qualitative standards.
Although the machine learning techniques used during this project were sophisticated, our team delivered a practical result that any trader can understand intuitively. This project is just one example of SS&C Eze’s commitment to building institutional knowledge in machine learning. Perhaps more profound is that projects such as this highlight only a small part of our dedication to innovation. Beyond the code, data, and collaborative discussions that comprised the actual experience of this project is the simple notion that great ideas can come from anywhere. And at SS&C Eze, we are always on the lookout for great ideas.
Have great ideas? View our open roles and apply today:

For more updates on innovation, AI, and ML, subscribe to our blog. And to stay up-to-date on the issues that matter most in the investment management community, subscribe to our newsletters.
This piece was written with contributions from the following individuals: Brian Tosado-Prater, Jai Crespo, Jonathan Myers.